
How to Build a RAG System for Your Business Documents Using Claude
Imagine asking a question about your company’s procurement policy and receiving an accurate, sourced answer in seconds, drawn directly from your internal documents. Not a generic response from an AI trained on public data, but a precise, contextually grounded answer from your own knowledge base. This is the promise of Retrieval Augmented Generation (RAG), and in 2026, it has moved firmly from experimental territory into production-ready reality for UK businesses.
According to research commissioned by DSIT (Department for Science, Innovation and Technology), 85% of UK AI adopters are using natural language processing and text generation tools, making document intelligence one of the most accessible and high-impact entry points into enterprise AI. Yet many businesses are still relying on keyword search tools from a decade ago. A well-architected RAG system, built on top of Anthropic’s Claude, changes that entirely.
In this guide, we will walk you through what a RAG business system actually is, how retrieval augmented generation works with Claude, the key architectural decisions you need to make, and practical steps to get your document AI knowledge base up and running.
What Is Retrieval Augmented Generation and Why Does It Matter?
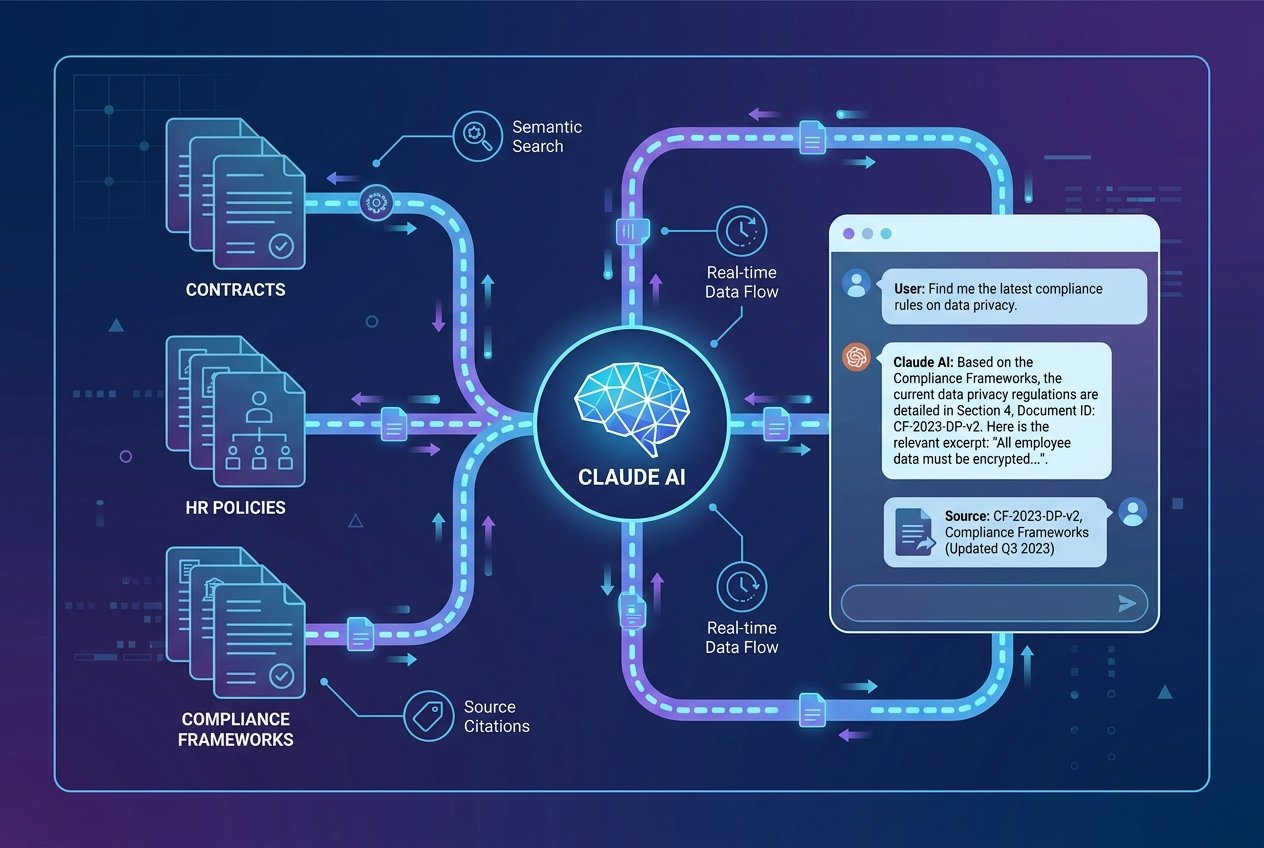
Retrieval Augmented Generation is an AI architecture that combines a search retrieval layer with a large language model (LLM) to produce accurate, grounded responses. Rather than relying solely on the LLM’s pre-trained knowledge, a RAG system retrieves relevant chunks of text from your own document repositories before passing them to the model for generation.
The result is a system that answers questions using your data, in your language, citing your documents. This is transformative for businesses dealing with large volumes of internal documentation including contracts, HR policies, product manuals, compliance frameworks, and standard operating procedures.
A key concern with standalone LLMs is hallucination: the tendency for models to confidently produce incorrect information. A properly implemented RAG system dramatically reduces this risk by grounding Claude’s responses in retrieved source documents. Anthropic’s own Contextual Retrieval research demonstrates that combining semantic embeddings with BM25 keyword search reduces failed retrievals by up to 49 to 67 percent, a significant accuracy gain for enterprise use cases.
According to the ONS Business Insights report from January 2026, 25% of UK businesses now use some form of AI, up 15 percentage points since 2023, with 44% of large enterprises already deploying AI tools. Critically, 75% of adopters report improved workforce productivity. For those yet to adopt document AI, the competitive gap is widening.
Why Claude Is Particularly Well-Suited for Document AI
Claude, developed by Anthropic, has emerged as a strong choice for enterprise RAG applications, particularly for businesses handling sensitive, nuanced, or complex documentation. Here is why it stands out as a knowledge base AI backbone:
- Extended context window: Claude supports context windows up to 200,000 tokens, allowing it to reason across lengthy documents and multiple retrieved chunks simultaneously.
- Instruction following: Claude is highly effective at following structured prompts, making it reliable for grounding responses strictly in retrieved content and refusing to guess when documents are silent on a topic.
- Anthropic’s native RAG integration: Claude’s Projects feature automatically triggers RAG mode when uploaded knowledge approaches the context limit, extending knowledge capacity by up to 10 times with minimal quality degradation.
- Enterprise safety and compliance alignment: Claude’s Constitutional AI training makes it well-suited for regulated sectors such as legal, financial services, and healthcare, which are prominent across the UK economy.
- Cost optimisation: Prompt caching for frequently accessed knowledge bases can reduce costs by approximately 90% and improve response latency by more than 2x, according to Anthropic’s enterprise deployment guidance.
The Core Architecture of a RAG System for Business Documents
Building a RAG business system involves five interconnected layers. Understanding each layer is essential before selecting tools or writing a single line of code.
Layer 1: Document Ingestion and Parsing
Your RAG pipeline begins with getting your documents into a processable format. This is often underestimated and can become the most time-consuming part of the build.
For most UK businesses, this involves processing a mix of PDFs, Word documents, PowerPoint files, spreadsheets, scanned images, and web pages. You will need a robust document parsing layer that handles:
- Multi-format extraction (PDF, DOCX, PPTX, XLSX)
- Optical character recognition (OCR) for scanned documents
- Preservation of document structure such as headings, tables, numbered clauses, and footnotes
- Metadata extraction including document title, author, version, effective date, and department
Tools such as Unstructured, DocLing, or AWS Textract are commonly used for this layer. For organisations already using SharePoint, Google Drive, or Confluence, native connectors from platforms like LlamaIndex or LangChain can dramatically speed up ingestion.
Layer 2: Contextual Chunking
Once your documents are parsed, they must be divided into chunks that can be retrieved individually. The 2026 best practice has moved well beyond naive fixed-size chunking, which often cuts across sentences or clauses, destroying meaning in the process.
Instead, leading practitioners now recommend semantic and section-aware chunking strategies:
- Split on natural boundaries such as headings, clause numbers, or paragraph breaks
- Apply an overlap of 50 to 150 tokens between adjacent chunks to preserve context at boundaries
- Target chunk sizes of 300 to 800 tokens depending on document type (shorter for legal clauses, longer for technical manuals)
- Attach rich metadata to every chunk including document ID, section title, clause number, effective date, and sensitivity classification
For legal and compliance documents in particular, clause-level chunking is recommended. This allows Claude to cite the specific clause that answers a question, dramatically improving auditability and user trust.
Layer 3: Embedding and Vector Storage
Each chunk is converted into a numerical vector representation using an embedding model. These vectors capture semantic meaning, enabling similarity searches that go far beyond keyword matching.
For an AI document search system built around Claude, strong embedding model options include Cohere Embed v3, BAAI BGE-large, and Amazon Bedrock embedding models for AWS-hosted deployments. The critical rule is to use the same model for both indexing chunks and encoding user queries.
These vectors are stored in a vector database. Common production choices for UK enterprise deployments include:
- pgvector (within PostgreSQL): ideal for organisations already running Postgres infrastructure
- Weaviate or Pinecone: strong managed options with hybrid search support
- Milvus: open-source and well-suited for high-volume enterprise workloads
Critically, your vector database should also support BM25-style keyword search alongside vector search. This dual capability is the foundation of Anthropic’s recommended Contextual Retrieval approach.
Layer 4: Hybrid Retrieval and Reranking
This is the layer that separates a mediocre document AI system from a genuinely production-ready one. Hybrid retrieval combines two complementary search strategies:
- Semantic vector search: finds chunks that are conceptually similar to the user’s query, even if exact keywords differ
- BM25 keyword search: finds chunks containing precise terminology, acronyms, or product names that semantic search might miss
Results from both searches are merged using Reciprocal Rank Fusion (RRF), a well-established technique that normalises and combines rankings from multiple retrieval signals. The top 50 to 100 candidates are then passed through an optional reranker, such as Cohere Rerank or a BGE cross-encoder, which re-scores them based on query-document relevance. The top 5 to 10 chunks are then passed to Claude.
This pipeline, aligned with Anthropic’s Contextual Retrieval methodology, is what delivers that 49 to 67 percent reduction in retrieval failures compared to naive single-vector approaches.
Layer 5: Prompt Construction and Claude Generation
The final layer brings everything together. Retrieved chunks are assembled into a structured prompt delivered to Claude, which then generates a grounded, cited response. Effective RAG prompts for Claude typically:
- Define a clear role (for example, “You are an HR policy assistant for Acme Ltd”)
- Present retrieved document chunks in a labelled format including source document name, section, and version
- Instruct Claude to cite sources and to say explicitly when the retrieved documents do not contain an answer
- Include any organisation-specific rules, such as always defaulting to the most recent document version
This structured approach ensures Claude behaves as a disciplined, document-grounded assistant rather than a free-ranging chatbot, which is essential for enterprise knowledge base AI use cases.
Security, Governance, and Compliance Considerations for UK Businesses
Any organisation deploying document AI in the UK must consider data governance from the outset. Key considerations include:
- Data residency: Ensure your vector database and AI API calls comply with UK GDPR requirements and, where applicable, sector-specific regulations such as FCA guidelines or NHS data frameworks.
- Role-based access control (RBAC): Your retrieval layer must enforce document-level permissions. A payroll document should not be retrievable by an unauthorised user simply because they asked the right question.
- Audit trails: Log which documents were retrieved for each query, enabling compliance reviews and helping diagnose inaccuracies.
- Document versioning: Implement version metadata so that retrieval always prioritises current, superseded-safe documents. Retrieving an outdated HR policy could create serious legal liability.
Regulated industries in particular should consider self-hosted or private cloud deployments where all data stays within organisational boundaries, rather than relying on third-party managed RAG platforms.
Practical Use Cases for UK Businesses
The value of a well-built RAG system for business documents becomes clearest when mapped to real operational pain points:
- Legal and compliance teams can query thousands of pages of contracts and regulatory guidance instantly, reducing research time from hours to minutes.
- HR departments can deploy a policy assistant that answers employee questions about entitlements, procedures, and conduct frameworks, drawing from the official handbook.
- Sales teams can search product documentation, pricing guides, and tender responses to surface relevant content for proposals.
- Finance departments can cross-reference audit documents, board papers, and financial policies without manually navigating SharePoint folder hierarchies.
- Customer support teams can resolve queries faster by accessing technical documentation through a natural language interface.
At Kaizen AI Consulting, we have helped UK businesses across these sectors design and deploy RAG systems that are genuinely fit for enterprise use: not quick demos, but governed, tested, production-grade implementations that integrate with existing infrastructure and workflows.
Agentic RAG: The Next Evolution
The 2026 landscape has introduced a significant evolution beyond standard RAG: agentic RAG. Rather than a single retrieval-generation loop, agentic systems can iteratively reformulate queries when initial retrieval fails, use multiple tools in sequence, and reason across multiple document sources before synthesising a final answer.
For example, an agentic document AI system might receive a complex query about a contractual obligation, retrieve relevant contract clauses, cross-reference them with associated regulatory guidance, and then produce a structured summary with source citations, all autonomously. According to AIMultiple’s 2026 analysis, agentic RAG frameworks are now capable of handling context windows of 1 to 2 million tokens, fundamentally changing what is possible in enterprise document intelligence.
This is a rapidly developing area, and the architectural choices you make today will determine how easily your RAG system can evolve into a more agentic deployment tomorrow.
Getting Started: Should You Build or Buy?
For most UK businesses, the choice is not purely between building from scratch and buying an off-the-shelf SaaS tool. The real decision is about where custom engineering adds strategic value versus where managed platforms are sufficient.
Managed platforms such as Vectara or Microsoft Azure AI Search offer faster time-to-value and require less engineering overhead. Custom builds using LangChain, LlamaIndex, and a self-hosted vector database offer greater control, auditability, and the ability to integrate deeply with proprietary systems.
The right answer depends on your document volumes, compliance requirements, integration needs, and internal engineering capability. Kaizen AI Consulting specialises in helping UK businesses navigate exactly this decision, designing RAG architectures that are proportionate to the organisation’s needs, scalable as those needs grow, and built with governance baked in from day one. If you are exploring how retrieval augmented generation could unlock the value trapped in your business documents, get in touch with our team today for a no-obligation discovery conversation.
Key Takeaways
- RAG business systems combine document retrieval with Claude’s language understanding to produce accurate, source-grounded answers from your own document libraries.
- Anthropic’s Contextual Retrieval methodology, combining semantic vector search with BM25 and reranking, reduces retrieval failures by 49 to 67 percent compared to basic approaches.
- Effective AI document search requires thoughtful chunking, hybrid retrieval, robust metadata, and role-based access controls.
- UK businesses in legal, HR, finance, compliance, and customer support stand to gain significant productivity improvements from well-implemented knowledge base Claude deployments.
- Whether you build or buy, governance, security, and auditability must be central to your architecture from the outset.
- Agentic RAG represents the next frontier, and the architectural decisions you make today should anticipate that evolution.
The organisations that invest in robust, governed document AI now will find themselves with a compounding operational advantage. The technology is mature, the tools are available, and the business case is clear. The question is not whether your business documents should become queryable intelligence assets, but how quickly you can make that a reality.